
详细介绍如何自研一款"博客搬家"功能
前言
该篇文章为DBlog开源博客新增博客迁移功能(支持多个站点)的修订版,补充了一些详细内容
现在的技术博客(社区)越来越多,比如:imooc、spring4All、csdn、cnblogs或者iteye等,有很多朋友可能在这些网站上都发表过博文,当有一天我们想自己搞一个博客网站时就会发现好多东西已经写过了,我们不可能再重新写一遍,况且多个平台上都有自己发表的文章,也不可能挨个去各个平台ctrl c + ctrl v。鉴于此, 我在我的开源博客里新开发了一个“博客迁移”的功能,目前支持imooc、csdn、iteye和cnblogs,后期会适配更多站点。
功能介绍
功能特点
使用方便,抓取规则已内置,只需修改很少的配置就可运行。支持同步抓取文章标签、description和keywords,支持转存图片文件。使用开源的国产爬虫框架webMagic,方便扩展爬虫功能。
使用教程
目前,该功能已内置了以下几个平台(imooc、csdn、cnblogs和iteye),根据不同的平台,程序已默认了一套抓取规则,如下图系列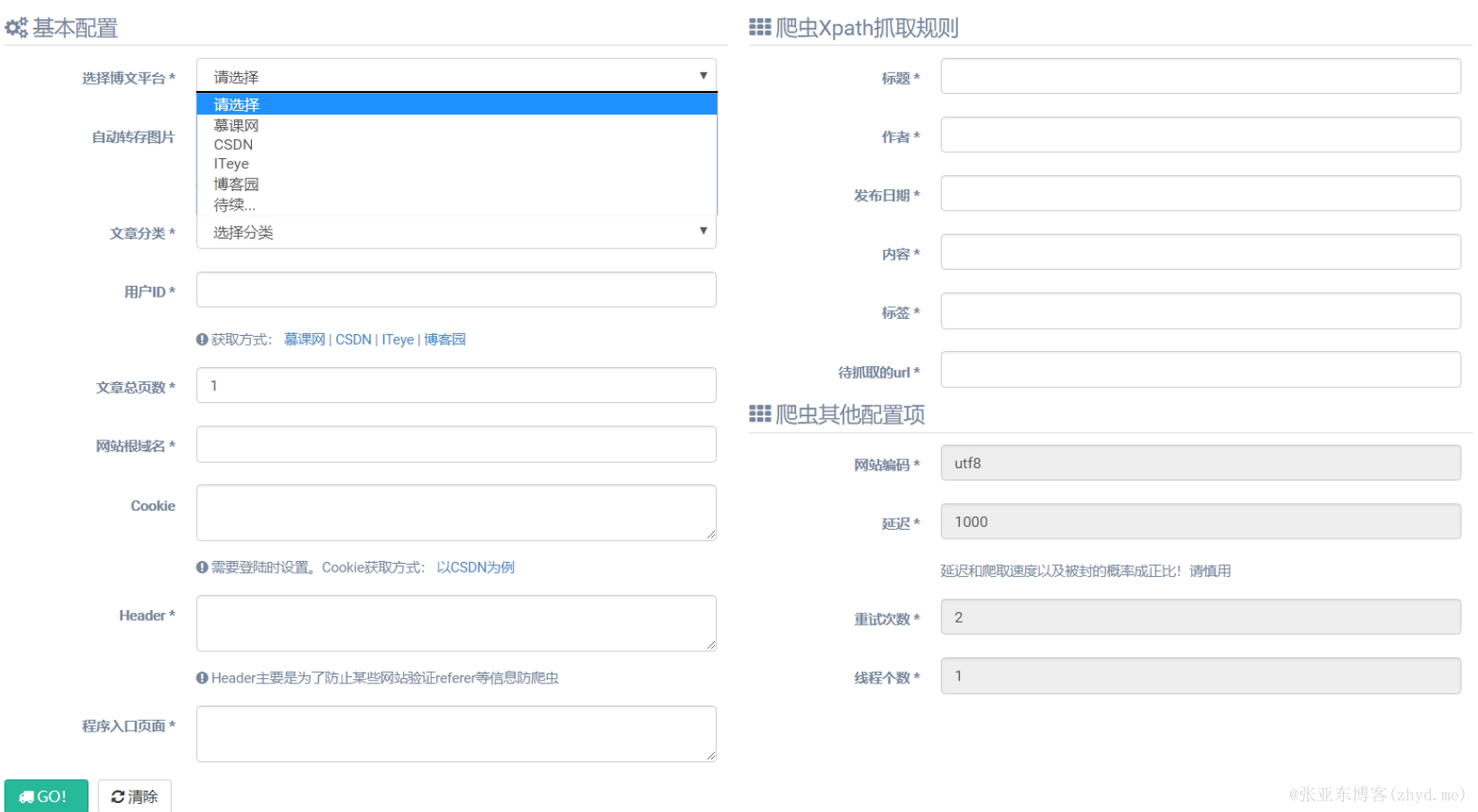
cnblogs抓取规则:
使用时,只需要手动指定以下几项配置即可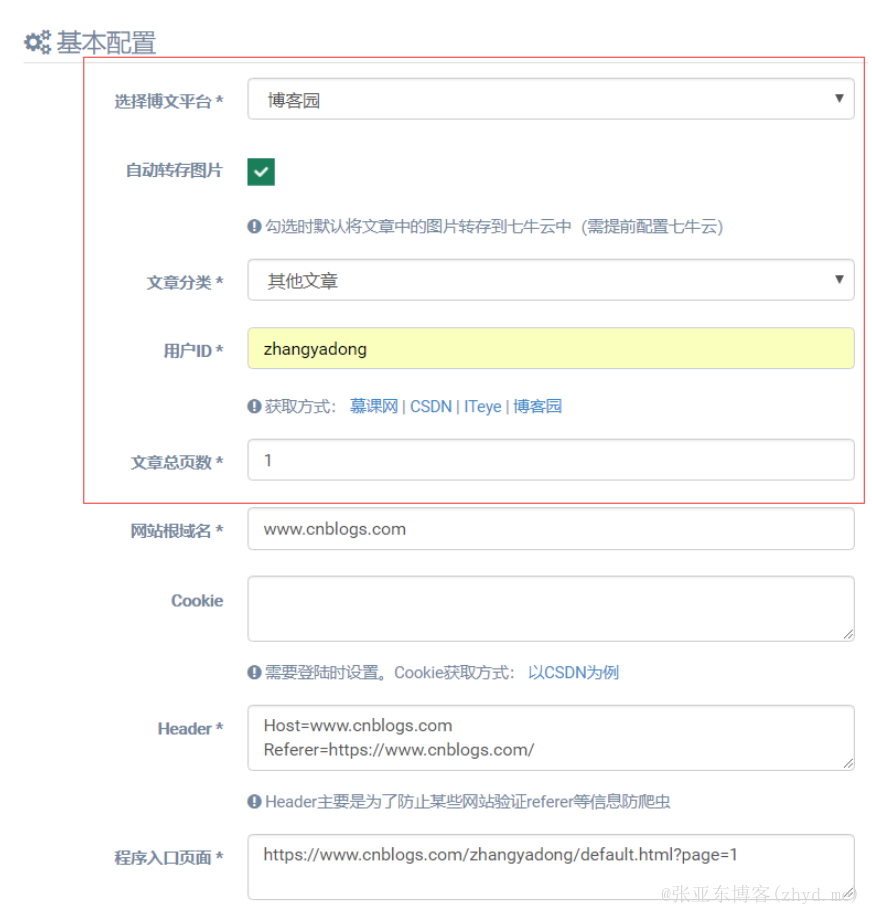
其他信息在选择完博文平台后,程序会自动补充完整。圈中必填的几项配置如下:
选择博文平台:选择待操作的博文平台(程序会自动生成对应平台的抓取规则)自动转存图片:勾选时默认将文章中的图片转存到七牛云中(需提前配置七牛云)文章分类:是指抓取的文章保存到本地数据库中的文章分类用户ID:是指各平台中,登陆完成后的用户ID,程序中已给出了对应获取的方法文章总页数:是指待抓取的用户所有文章的页数Cookie(非必填):只在必须需要登陆才能获取数据时指定,获取方式如程序中所示
在指定完博文平台、用户ID和文章总页数后,爬虫的其他配置项就会自动补充完整,最后直接执行该程序即可。 注意:默认同步过来的文章为“草稿”状态,主要是为了防止抓取的内容错误,而直接显示到网站前台,造成不必要的麻烦。所以,需要手动确认无误后修改发布状态。另外,针对一些做了防盗链的网站,我们在使用“文章搬运工”时,还要勾选上“自动转存图片”,至于为何要这么做,在下面会有解释。
关于“文章搬运工”功能的实现
“文章搬运工”功能听起来觉得高大上,类似的比如CSDN和cnblogs里的“博客搬家”功能,其实实现起来很简单。下面听我道一道,你也可以轻松做出一个“博客搬家”功能!
“博客搬家”首先需要克服的问题无非就是:怎么从别人的页面中提取出相关的文章信息后保存到自己的服务器中。说到页面提取,可能很多同学不约而同的就想到了:爬虫!没错,就是通过最基础的网络爬虫就可实现,而OneBlog的文章搬运工功能就是基于爬虫实现的。
OneBlog中选用了国产的优秀的开源爬虫框架:webMagic。
WebMagic是一个简单灵活的Java爬虫框架。之所以选择该框架,完全依赖于它的优秀特性:
完全模块化的设计,强大的可扩展性。
核心简单但是涵盖爬虫的全部流程,灵活而强大,也是学习爬虫入门的好材料。
提供丰富的抽取页面API。
无配置,但是可通过POJO+注解形式实现一个爬虫。
支持多线程。
支持分布式。
支持爬取js动态渲染的页面。
无框架依赖,可以灵活的嵌入到项目中去
关于webMagic的其他详细介绍,请去webMagic的官网查阅,本文不做赘述。
下面针对OneBlog中的“文章搬运工”功能做一下简单的分析。
第一步,在pom中添加webMagic最新的依赖包
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
第二步,为了方便扩展,我们要抽象出webMagic爬虫运行时需要的基本属性到BaseModel.java
/**
* @author yadong.zhang (yadong.zhang0415(a)gmail.com)
* @website https://www.zhyd.me
* @version 1.0
* @date 2018/7/23 13:33
*/
@Data
public class BaseModel {
@NotEmpty(message = "必须指定标题抓取规则(xpath)")
private String titleRegex;
@NotEmpty(message = "必须指定内容抓取规则(xpath)")
private String contentRegex;
@NotEmpty(message = "必须指定发布日期抓取规则(xpath)")
private String releaseDateRegex;
@NotEmpty(message = "必须指定作者抓取规则(xpath)")
private String authorRegex;
@NotEmpty(message = "必须指定待抓取的url抓取规则(xpath)")
private String targetLinksRegex;
private String tagRegex;
private String keywordsRegex = "//meta [@name=keywords]/@content";
private String descriptionRegex = "//meta [@name=description]/@content";
@NotEmpty(message = "必须指定网站根域名")
private String domain;
private String charset = "utf8";
/**
* 每次爬取页面时的等待时间
*/
@Max(value = 5000, message = "线程间隔时间最大只能指定为5000毫秒")
@Min(value = 1000, message = "线程间隔时间最小只能指定为1000毫秒")
private int sleepTime = 1000;
/**
* 抓取失败时重试的次数
*/
@Max(value = 5, message = "抓取失败时最多只能重试5次")
@Min(value = 1, message = "抓取失败时最少只能重试1次")
private int retryTimes = 2;
/**
* 线程个数
*/
@Max(value = 5, message = "最多只能开启5个线程(线程数量越多越耗性能)")
@Min(value = 1, message = "至少要开启1个线程")
private int threadCount = 1;
/**
* 抓取入口地址
*/
// @NotEmpty(message = "必须指定待抓取的网址")
private String[] entryUrls;
/**
* 退出方式{1:等待时间(waitTime必填),2:抓取到的url数量(urlCount必填)}
*/
private int exitWay = 1;
/**
* 单位:秒
*/
private int waitTime = 60;
private int urlCount = 100;
private List<Cookie> cookies = new ArrayList<>();
private Map<String, String> headers = new HashMap<>();
private String ua = "Mozilla/5.0 (ozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36";
private String uid;
private Integer totalPage;
/* 保留字段,针对ajax渲染的页面 */
private Boolean ajaxRequest = false;
/* 是否转存图片 */
private boolean convertImg = false;
public String getUid() {
return uid;
}
public BaseModel setUid(String uid) {
this.uid = uid;
return this;
}
public Integer getTotalPage() {
return totalPage;
}
public BaseModel setTotalPage(Integer totalPage) {
this.totalPage = totalPage;
return this;
}
public BaseModel setTitleRegex(String titleRegex) {
this.titleRegex = titleRegex;
return this;
}
public BaseModel setContentRegex(String contentRegex) {
this.contentRegex = contentRegex;
return this;
}
public BaseModel setReleaseDateRegex(String releaseDateRegex) {
this.releaseDateRegex = releaseDateRegex;
return this;
}
public BaseModel setAuthorRegex(String authorRegex) {
this.authorRegex = authorRegex;
return this;
}
public BaseModel setTargetLinksRegex(String targetLinksRegex) {
this.targetLinksRegex = targetLinksRegex;
return this;
}
public BaseModel setTagRegex(String tagRegex) {
this.tagRegex = tagRegex;
return this;
}
public BaseModel setKeywordsRegex(String keywordsRegex) {
this.keywordsRegex = keywordsRegex;
return this;
}
public BaseModel setDescriptionRegex(String descriptionRegex) {
this.descriptionRegex = descriptionRegex;
return this;
}
public BaseModel setDomain(String domain) {
this.domain = domain;
return this;
}
public BaseModel setCharset(String charset) {
this.charset = charset;
return this;
}
public BaseModel setSleepTime(int sleepTime) {
this.sleepTime = sleepTime;
return this;
}
public BaseModel setRetryTimes(int retryTimes) {
this.retryTimes = retryTimes;
return this;
}
public BaseModel setThreadCount(int threadCount) {
this.threadCount = threadCount;
return this;
}
public BaseModel setEntryUrls(String[] entryUrls) {
this.entryUrls = entryUrls;
return this;
}
public BaseModel setEntryUrls(String entryUrls) {
if (StringUtils.isNotEmpty(entryUrls)) {
this.entryUrls = entryUrls.split("\r\n");
}
return this;
}
public BaseModel setExitWay(int exitWay) {
this.exitWay = exitWay;
return this;
}
public BaseModel setWaitTime(int waitTime) {
this.waitTime = waitTime;
return this;
}
public BaseModel setHeader(String key, String value) {
Map<String, String> headers = this.getHeaders();
headers.put(key, value);
return this;
}
public BaseModel setHeader(String headersStr) {
if (StringUtils.isNotEmpty(headersStr)) {
String[] headerArr = headersStr.split("\r\n");
for (String s : headerArr) {
String[] header = s.split("=");
setHeader(header[0], header[1]);
}
}
return this;
}
public BaseModel setCookie(String domain, String key, String value) {
List<Cookie> cookies = this.getCookies();
cookies.add(new Cookie(domain, key, value));
return this;
}
public BaseModel setCookie(String cookiesStr) {
if (StringUtils.isNotEmpty(cookiesStr)) {
List<Cookie> cookies = this.getCookies();
String[] cookieArr = cookiesStr.split(";");
for (String aCookieArr : cookieArr) {
String[] cookieNode = aCookieArr.split("=");
if (cookieNode.length <= 1) {
continue;
}
cookies.add(new Cookie(cookieNode[0].trim(), cookieNode[1].trim()));
}
}
return this;
}
public BaseModel setAjaxRequest(boolean ajaxRequest) {
this.ajaxRequest = ajaxRequest;
return this;
}
}
如上方代码中所示,我们抽取出了基本的抓取规则和针对不同平台设置的网站属性(domain、cookies和headers等)。
第三步,因为“博客迁移功能”目前只涉及到页面的解析、抽取,所以,我们只需要实现webMagic的PageProcessor接口即可。这里有个关键点需要注意:随着网络技术的发展,现在前后端分离的网站越来越多,而前后端分离的网站基本通过ajax渲染页面。这种情况下,httpClient获取到的页面内容只是js渲染前的html,因此按照常规的解析方式,是解析不到这部分内容的,因此我们需要针对普通的html页面和js渲染的页面分别提供解析器。本文主要讲解针对普通html的解析方式,至于针对js渲染的页面的解析,以后会另行写文介绍。
/**
* 统一对页面进行解析处理
*
* @author yadong.zhang (yadong.zhang0415(a)gmail.com)
* @version 1.0
* @website https://www.zhyd.me
* @date 2018/7/31 17:37
*/
@Slf4j
public class BaseProcessor implements PageProcessor {
private static BaseModel model;
BaseProcessor() {
}
BaseProcessor(BaseModel m) {
model = m;
}
@Override
public void process(Page page) {
Processor processor = new HtmlProcessor();
if (model.getAjaxRequest()) {
processor = new JsonProcessor();
}
processor.process(page, model);
}
@Override
public Site getSite() {
Site site = Site.me()
.setCharset(model.getCharset())
.setDomain(model.getDomain())
.setSleepTime(model.getSleepTime())
.setRetryTimes(model.getRetryTimes());
//添加抓包获取的cookie信息
List<Cookie> cookies = model.getCookies();
if (CollectionUtils.isNotEmpty(cookies)) {
for (Cookie cookie : cookies) {
if (StringUtils.isEmpty(cookie.getDomain())) {
site.addCookie(cookie.getName(), cookie.getValue());
continue;
}
site.addCookie(cookie.getDomain(), cookie.getName(), cookie.getValue());
}
}
//添加请求头,有些网站会根据请求头判断该请求是由浏览器发起还是由爬虫发起的
Map<String, String> headers = model.getHeaders();
if (MapUtils.isNotEmpty(headers)) {
Set<Map.Entry<String, String>> entrySet = headers.entrySet();
for (Map.Entry<String, String> entry : entrySet) {
site.addHeader(entry.getKey(), entry.getValue());
}
}
return site;
}
}
Processor.java接口,只提供一个process方法供实际的解析器实现
/**
* 页面解析接口
*
* @author yadong.zhang (yadong.zhang0415(a)gmail.com)
* @version 1.0
* @website https://www.zhyd.me
* @date 2018/7/31 17:37
*/
public interface Processor {
void process(Page page, BaseModel model);
}
HtmlProcessor.java
/**
* 解析处理普通的Html网页
*
* @author yadong.zhang (yadong.zhang0415(a)gmail.com)
* @version 1.0
* @website https://www.zhyd.me
* @date 2018/7/31 17:37
*/
public class HtmlProcessor implements Processor {
@Override
public void process(Page page, BaseModel model) {
Html pageHtml = page.getHtml();
String title = pageHtml.xpath(model.getTitleRegex()).get();
String source = page.getRequest().getUrl();
if (!StringUtils.isEmpty(title) && !"null".equals(title) && !Arrays.asList(model.getEntryUrls()).contains(source)) {
page.putField("title", title);
page.putField("source", source);
page.putField("releaseDate", pageHtml.xpath(model.getReleaseDateRegex()).get());
page.putField("author", pageHtml.xpath(model.getAuthorRegex()).get());
page.putField("content", pageHtml.xpath(model.getContentRegex()).get());
page.putField("tags", pageHtml.xpath(model.getTagRegex()).all());
page.putField("description", pageHtml.xpath(model.getDescriptionRegex()).get());
page.putField("keywords", pageHtml.xpath(model.getKeywordsRegex()).get());
}
page.addTargetRequests(page.getHtml().links().regex(model.getTargetLinksRegex()).all());
}
}
JsonProcessor.java
/**
* 解析处理Ajax渲染的页面(待完善)
*
* @author yadong.zhang (yadong.zhang0415(a)gmail.com)
* @version 1.0
* @website https://www.zhyd.me
* @date 2018/7/31 17:37
*/
public class JsonProcessor implements Processor {
@Override
public void process(Page page, BaseModel model) {
String rawText = page.getRawText();
String title = new JsonPathSelector(model.getTitleRegex()).select(rawText);
if (!StringUtils.isEmpty(title) && !"null".equals(title)) {
page.putField("title", title);
page.putField("releaseDate", new JsonPathSelector(model.getReleaseDateRegex()).select(rawText));
page.putField("author", new JsonPathSelector(model.getAuthorRegex()).select(rawText));
page.putField("content", new JsonPathSelector(model.getContentRegex()).select(rawText));
page.putField("source", page.getRequest().getUrl());
}
page.addTargetRequests(page.getHtml().links().regex(model.getTargetLinksRegex()).all());
}
}
第四步,定义爬虫的入口类ArticleSpiderProcessor.java。此步不多做解释,就是最基本启动爬虫,然后通过自定义Pipeline对数据进行组装
/**
* 爬虫入口
*
* @author yadong.zhang (yadong.zhang0415(a)gmail.com)
* @version 1.0
* @website https://www.zhyd.me
* @date 2018/7/23 10:38
*/
@Slf4j
public class ArticleSpiderProcessor extends BaseProcessor implements BaseSpider<Article> {
private BaseModel model;
private PrintWriter writer;
private ValidatorFactory factory = Validation.buildDefaultValidatorFactory();
private ArticleSpiderProcessor() {
}
public ArticleSpiderProcessor(BaseModel model, PrintWriter writer) {
super(model);
this.model = model;
this.writer = writer;
}
public ArticleSpiderProcessor(BaseModel model) {
super(model);
this.model = model;
}
/**
* 运行爬虫并返回结果
*
* @return
*/
@Override
public List<Article> run() {
List<String> errors = validateModel(model);
if (CollectionUtils.isNotEmpty(errors)) {
WriterUtil.writer2Html(writer, "校验不通过!请依据下方提示,检查输入参数是否正确......");
for (String error : errors) {
WriterUtil.writer2Html(writer, ">> " + error);
}
return null;
}
List<Article> articles = new LinkedList<>();
WriterUtil.writer2Html(writer, ">> 爬虫初始化完成,共需抓取 " + model.getTotalPage() + " 页数据...");
Spider spider = Spider.create(new ArticleSpiderProcessor())
.addUrl(model.getEntryUrls())
.addPipeline((resultItems, task) -> {
Map<String, Object> map = resultItems.getAll();
String title = String.valueOf(map.get("title"));
if (StringUtils.isEmpty(title) || "null".equals(title)) {
return;
}
String content = String.valueOf(map.get("content"));
String source = String.valueOf(map.get("source"));
String releaseDate = String.valueOf(map.get("releaseDate"));
String author = String.valueOf(map.get("author"));
String description = String.valueOf(map.get("description"));
description = StringUtils.isNotEmpty(description) ? description.replaceAll("\r\n| ", "")
: content.length() > 100 ? content.substring(0, 100) : content;
String keywords = String.valueOf(map.get("keywords"));
keywords = StringUtils.isNotEmpty(keywords) && !"null".equals(keywords) ? keywords.replaceAll(" +|,", ",").replaceAll(",,", ",") : null;
List<String> tags = (List<String>) map.get("tags");
log.info(String.format(">> 正在抓取 -- %s -- %s -- %s -- %s", source, title, releaseDate, author));
WriterUtil.writer2Html(writer, String.format(">> 正在抓取 -- <a href=\"%s\" target=\"_blank\">%s</a> -- %s -- %s", source, title, releaseDate, author));
articles.add(new Article(title, content, author, releaseDate, source, description, keywords, tags));
})
.thread(model.getThreadCount());
// 启动爬虫
spider.run();
return articles;
}
private <T> List<String> validateModel(T t) {
Validator validator = factory.getValidator();
Set<ConstraintViolation<T>> constraintViolations = validator.validate(t);
List<String> messageList = new ArrayList<>();
for (ConstraintViolation<T> constraintViolation : constraintViolations) {
messageList.add(constraintViolation.getMessage());
}
return messageList;
}
}
第五步,提取html规则,运行测试。以我的博客园为例,爬虫的一般以文章列表页作为入口页面,本文示例为:https://www.cnblogs.com/zhangyadong/ ,然后我们需要手动提取文章相关内容的抓取规则(OneBlog中主要使用Xsoup-XPath解析器,使用方式参考链接)。以推荐一款自研的Java版开源博客系统OneBlog一文为例
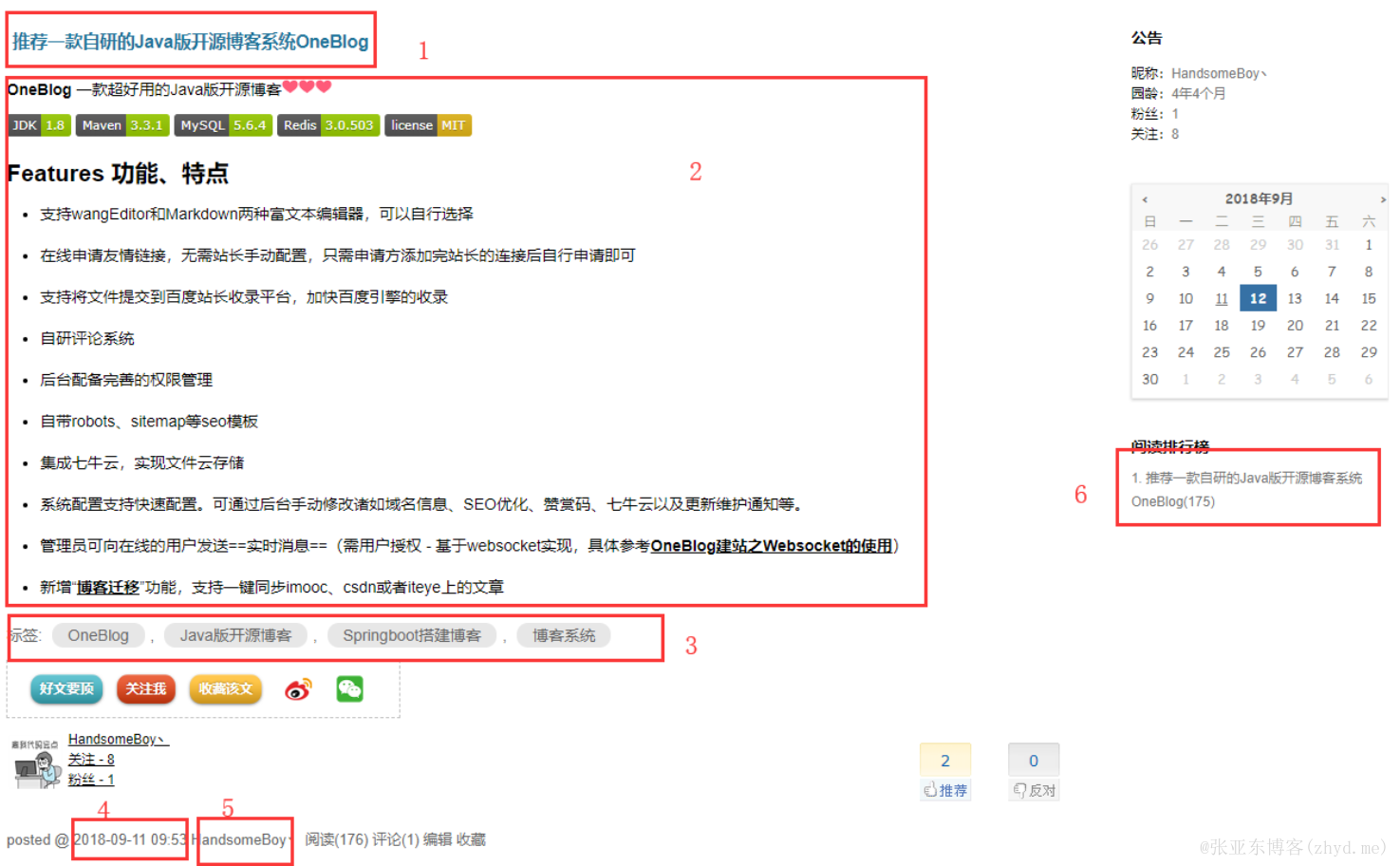
如图所示,需要抽取的一共为六部分:
文章标题
文章正文内容
文章标签
文章发布日期
文章作者
待抽取的其他文章列表
通过f12查看页面结构,如下
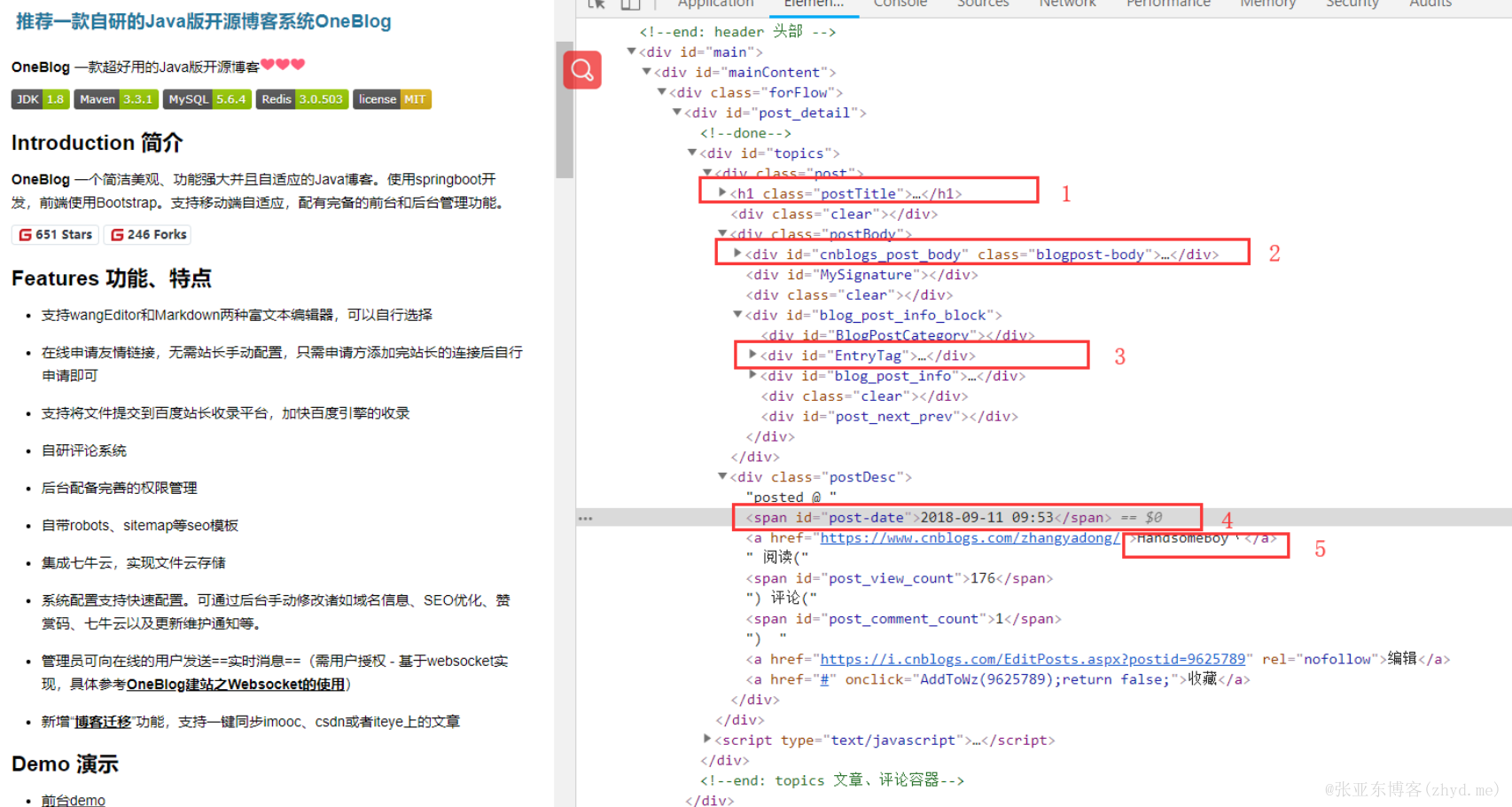
整理相关规则如下:
标题:"//a[@id=cb_post_title_url]/html()"
文章正文:"//div[@id=cnblogs_post_body]/html()"
标签:"//div[@id=EntryTag]/a/html()"
发布日期:"//span[@id=post-date]/html()"
作者:"//div[@class=postDesc]/a[1]/html()"
待抽取的其他文章链接:".*www\.cnblogs\.com/zhangyadong/p/[\w\d]+\.html"
注:“待抽取的其他文章链接”就是根据这篇文章的链接抽取出的规则
到这一步为止,基本的文章信息抽取规则就以获取完毕,接下来就跑一下测试
@Test
public void cnblogSpiderTest() {
BaseSpider<Article> spider = new ArticleSpiderProcessor(new CnblogModel().setUid("zhangyadong")
.setTotalPage(1)
.setDomain("www.cnblogs.com")
.setTitleRegex("//a[@id=cb_post_title_url]/html()")
.setAuthorRegex("//div[@class=postDesc]/a[1]/html()")
.setReleaseDateRegex("//span[@id=post-date]/html()")
.setContentRegex("//div[@id=cnblogs_post_body]/html()")
.setTagRegex("//div[@id=EntryTag]/a/html()")
.setTargetLinksRegex(".*www\\.cnblogs\\.com/zhangyadong/p/[\\w\\d]+\\.html")
.setHeader("Host", "www.cnblogs.com")
.setHeader("Referer", "https://www.cnblogs.com/"));
spider.run();
}
Console控制台打印数据
2018-09-12 11:50:49 [us.codecraft.webmagic.Spider:306] INFO - Spider www.cnblogs.com started!
2018-09-12 11:50:51 [com.zyd.blog.spider.processor.ArticleSpiderProcessor:89] INFO - >> 正在抓取 -- https://www.cnblogs.com/zhangyadong/p/oneblog.html -- 推荐一款自研的Java版开源博客系统OneBlog -- 2018-09-11 09:53 -- HandsomeBoy丶
2018-09-12 11:50:52 [us.codecraft.webmagic.Spider:338] INFO - Spider www.cnblogs.com closed! 2 pages downloaded.
如上,文章已成功被抓取,剩下的,无非就是要么保存到文件中,要么持久化到数据库里。OneBlog中是直接保存到了数据库里。
关于文章图片转存
为什么要添加“文章转存”功能?那是因为一些网站对本站内的静态资源做了“防盗链”,而所谓的“防盗链”说简单点就是:我的东西别人不能用,得需要我授权才可。这样做的好处就是,不会让自己的劳动成果白白给别人做了嫁衣。那么,针对这一特性,如果在“文章搬运”时,原文图片未经处理就原封不动的保存下来,以开源博客这篇文章为例,可能就会碰到如下情况

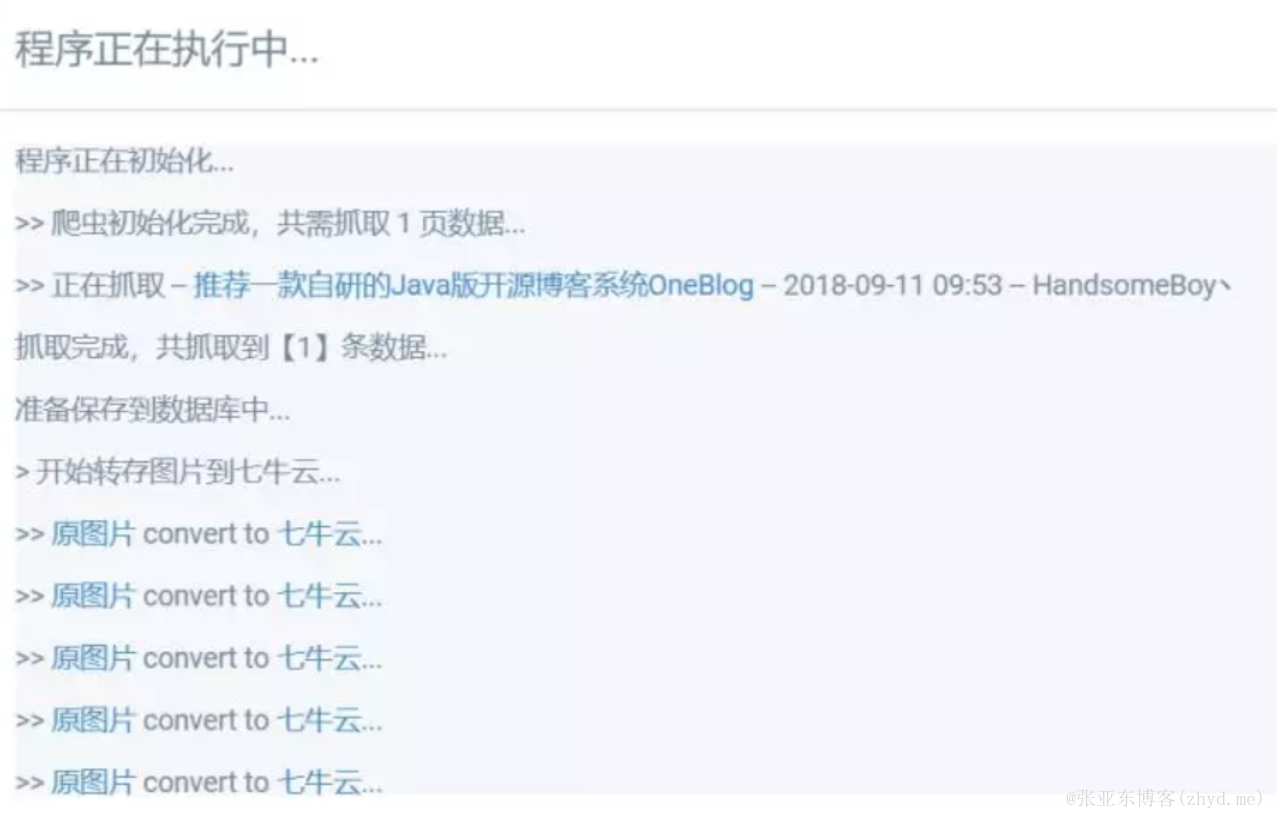
如上图,有一些图片无法显示,在控制台中可以看到这些图片全是报错403,也就是未授权,也就是所谓的被原站做了“防盗链”!这个时候,我们在抓取文章时就需要将原文的图片全部转存到自己服务器上,如此一来就解决了“被防盗链”的问题。
针对这一问题,OneBlog中则是通过正则表达式,将所有img标签的src里的网络文件下载下来后转存到七牛云中。简单代码如下:
private static final Pattern PATTERN = Pattern.compile("<img[^>]+src\\s*=\\s*['\"]([^'\"]+)['\"][^>]*>");
private String parseImgForHtml(String html, String qiniuBasePath, PrintWriter writer) {
if (StringUtils.isEmpty(html)) {
return null;
}
Matcher m = PATTERN.matcher(html);
Set<String> imgUrlSet = new HashSet<>();
while (m.find()) {
String imgUrl = m.group(1);
imgUrlSet.add(imgUrl);
}
if (!CollectionUtils.isEmpty(imgUrlSet)) {
WriterUtil.writer2Html(writer, " > 开始转存图片到七牛云...");
for (String imgUrl : imgUrlSet) {
String qiniuImgPath = ImageDownloadUtil.convertToQiniu(imgUrl);
if (StringUtils.isEmpty(qiniuImgPath)) {
WriterUtil.writer2Html(writer, " >> 图片转存失败,请确保七牛云以配置完毕!请查看控制台详细错误信息...");
continue;
}
html = html.replaceAll(imgUrl, qiniuBasePath + qiniuImgPath);
WriterUtil.writer2Html(writer, String.format(" >> <a href=\"%s\" target=\"_blank\">原图片</a> convert to <a href=\"%s\" target=\"_blank\">七牛云</a>...", imgUrl, qiniuImgPath));
}
}
return html;
}
ImageDownloadUtil.convertToQiniu方法如下
/**
* 将网络图片转存到七牛云
*
* @param imgUrl 网络图片地址
*/
public static String convertToQiniu(String imgUrl) {
log.debug("download img >> %s", imgUrl);
String qiniuImgPath = null;
try (InputStream is = getInputStreamByUrl(checkUrl(imgUrl));
ByteArrayOutputStream outStream = new ByteArrayOutputStream();) {
byte[] buffer = new byte[1024];
int len = 0;
while ((len = is.read(buffer)) != -1) {
outStream.write(buffer, 0, len);
}
qiniuImgPath = QiniuApi.getInstance()
.withFileName("temp." + getSuffixByUrl(imgUrl), QiniuUploadType.SIMPLE)
.upload(outStream.toByteArray());
} catch (Exception e) {
log.error("Error.", e);
}
return qiniuImgPath;
}
(注:以上代码只是简单示例了一下核心代码,具体代码请参考我的开源博客:OneBlog)
总结
看完了我上面的介绍,你应该可以发现,其实技术实现起来,并没有太大的难点。主要重难点无非就一个:如何编写提取html内容的规则。规则一旦确定了,剩下的无非就是粘贴复制就能完成的代码而已。
最后声明
1.本工具开发初衷只是用来迁移 自己的文章 所用,因此不可用该工具恶意窃取他人劳动成果!
2.因不听劝阻,使用该工具恶意窃取他们劳动成果而造成的一切不良后果,本人表示:坚决不背锅!
3.如果该工具不好用,你们绝对不能打我!
4.有问题、建议,请留言,或者去gitee上提Issues!
最后打个广告,如果你觉得这篇文章对你有用,可以关注我的技术公众号:码一码,你的关注和转发是对我最大的支持,O(∩_∩)O

- 本文标签: Spring Boot OneBlog 码一码 博客迁移
- 本文链接: https://www.zhyd.me/article/120
- 版权声明: 本文由张亚东原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐









相关文章
关于我

近期评论
-
来自: JustAuth于2019年7月21日正式喜提码云【GVP 】称号

-
来自: 留言板
-
来自: 暴露真实IP真的没关系吗?

-
来自: 留言板
-
来自: 留言板